
Dolt is the world’s first and only version controlled SQL database. We’re starting to realize, somewhat serendipitously, Dolt is also the perfect database for agents. It’s not just me, Cursor thinks so too. Databases need branches for agents to work on. Humans need diffs to review what the agent has done.
Last week we covered how Dolt can be used for agentic data cleaning. This week, we cover how Dolt helps with agentic schema design. We will use Claude Code to design a simple schema. As you’ll see through this example, Dolt is the perfect database to pair with agents.
The Set Up#
First, we create a new Dolt database called test-schema-design using dolt init.
$ mkdir test-schema-design
$ cd test-schema-design
$ dolt initWith Claude Code, you can create a CLAUDE.md file that is kind of like the system prompt for any invocation of claude in this directory. I wanted claude to know this was a Dolt database directory because that would be unclear from the contents which is only a .dolt directory. This CLAUDE.md was enough to get Claude Code to use Dolt.
$ cat CLAUDE.md
This directory contains a dolt database.
You can access the dolt command line by typing dolt.
dolt is like git for sql databases so all git commands work the same in dolt.
There is a no sql-server available so you will have to do everything via the dolt command line.
The database will start empty. This project is to see how well you perform on schema design.Model an Employees Database#
Our Getting Started guide uses a simple employees database to show off Dolt. Let’s see how Claude Code does building something similar.
I started claude in the above director and provided the following prompt.
I would like to create a simple employee resource planning database. I
want to start by modeling employees and teams. Can you create a sql
schema in dolt that does this?Fairly quickly, my Dolt database was populated with this schema.
$ dolt schema show
employees @ working
CREATE TABLE `employees` (
`id` int NOT NULL AUTO_INCREMENT,
`first_name` varchar(50) NOT NULL,
`last_name` varchar(50) NOT NULL,
`email` varchar(100) NOT NULL,
`phone` varchar(20),
`job_title` varchar(100),
`team_id` int,
`hire_date` date,
`salary` decimal(10,2),
`status` enum('active','inactive','terminated') DEFAULT '1',
`created_at` timestamp DEFAULT CURRENT_TIMESTAMP,
`updated_at` timestamp DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
UNIQUE KEY `email` (`email`),
KEY `team_id` (`team_id`),
CONSTRAINT `employees_ibfk_1` FOREIGN KEY (`team_id`) REFERENCES `teams` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin;
teams @ working
CREATE TABLE `teams` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(100) NOT NULL,
`description` text,
`manager_id` int,
`created_at` timestamp DEFAULT CURRENT_TIMESTAMP,
`updated_at` timestamp DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `manager_id` (`manager_id`),
UNIQUE KEY `name` (`name`),
CONSTRAINT `teams_ibfk_1` FOREIGN KEY (`manager_id`) REFERENCES `employees` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin;This is pretty good. The columns mostly seem relevant. claude created proper foreign key references.
Remove Extraneous Columns#
A couple critiques:
- The
created_atandupdated_atcolumns are redundant with Dolt’s version control functionality. - A potential limitation is this schema supports only one team per employee.
Let’s fix the first one.
The created_at and updated_at columns on both table are rededundant with
Dolt's version control functionality. Dolt supports the information in
those columns implicitly via it's commit graph. Can you please remove
them?claude was getting a bit excited so I had to instruct it to not commit the changes before I reviewed them.
Can you not commit the changes at the end to give me a chance to review?
Please reset soft to the previous commit.After that quick scolding I had a diff to review. Here in lies the power of Dolt! You can review what the AI did to make sure it is correct.
$ dolt diff
diff --dolt a/employees b/employees
--- a/employees
+++ b/employees
CREATE TABLE `employees` (
`id` varchar(36) NOT NULL DEFAULT (uuid()),
`first_name` varchar(50) NOT NULL,
`last_name` varchar(50) NOT NULL,
`email` varchar(100) NOT NULL,
`phone` varchar(20),
`job_title` varchar(100),
`team_id` varchar(36),
`hire_date` date,
`salary` decimal(10,2),
`status` enum('active','inactive','terminated') DEFAULT '1',
- `created_at` timestamp DEFAULT CURRENT_TIMESTAMP,
- `updated_at` timestamp DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
UNIQUE KEY `email` (`email`),
KEY `team_id` (`team_id`),
CONSTRAINT `employees_ibfk_1` FOREIGN KEY (`team_id`) REFERENCES `teams` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin;
diff --dolt a/teams b/teams
--- a/teams
+++ b/teams
CREATE TABLE `teams` (
`id` varchar(36) NOT NULL DEFAULT (uuid()),
`name` varchar(100) NOT NULL,
`description` text,
`manager_id` varchar(36),
- `created_at` timestamp DEFAULT CURRENT_TIMESTAMP,
- `updated_at` timestamp DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `manager_id` (`manager_id`),
UNIQUE KEY `name` (`name`),
CONSTRAINT `teams_ibfk_1` FOREIGN KEY (`manager_id`) REFERENCES `employees` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin;This looks good now.
UUID Keys#
Now, let’s make those keys UUIDs instead of AUTO_INCREMENT. Dolt works better with UUID keys.
Dolt does better with UUID primary keys can you change the auto increment
primary keys to auto-generated uuids?And voila.
$ dolt diff
diff --dolt a/employees b/employees
--- a/employees
+++ b/employees
CREATE TABLE `employees` (
- `id` int NOT NULL AUTO_INCREMENT,
+ `id` varchar(36) NOT NULL DEFAULT (uuid()),
`first_name` varchar(50) NOT NULL,
`last_name` varchar(50) NOT NULL,
`email` varchar(100) NOT NULL,
`phone` varchar(20),
`job_title` varchar(100),
- `team_id` int,
+ `team_id` varchar(36),
`hire_date` date,
`salary` decimal(10,2),
`status` enum('active','inactive','terminated') DEFAULT '1',
`created_at` timestamp DEFAULT CURRENT_TIMESTAMP,
`updated_at` timestamp DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
UNIQUE KEY `email` (`email`),
KEY `team_id` (`team_id`),
CONSTRAINT `employees_ibfk_1` FOREIGN KEY (`team_id`) REFERENCES `teams` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin;
Primary key sets differ between revisions for table 'employees', skipping data diff
diff --dolt a/teams b/teams
--- a/teams
+++ b/teams
CREATE TABLE `teams` (
- `id` int NOT NULL AUTO_INCREMENT,
+ `id` varchar(36) NOT NULL DEFAULT (uuid()),
`name` varchar(100) NOT NULL,
`description` text,
- `manager_id` int,
+ `manager_id` varchar(36),
`created_at` timestamp DEFAULT CURRENT_TIMESTAMP,
`updated_at` timestamp DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `manager_id` (`manager_id`),
UNIQUE KEY `name` (`name`),
CONSTRAINT `teams_ibfk_1` FOREIGN KEY (`manager_id`) REFERENCES `employees` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin;Again, the power of diffs to review. claude made sure to update the types in the referenced columns. This looks good.
Test Data#
Now, let’s add some test data. I added this data on main but you could also do it on a test_data branch if you want to keep main for production data.
looks good please commit and then lets add some dummy test data so we can
validate queries workThe data looks reasonable, again, taking advantage of Dolt’s schema and data diff capabilities.
$ dolt diff
diff --dolt a/employees b/employees
--- a/employees
+++ b/employees
+---+--------------------------------------+------------+-----------+---------------------------+----------+--------------------------+--------------------------------------+------------+----------+--------+---------------------+---------------------+
| | id | first_name | last_name | email | phone | job_title | team_id | hire_date | salary | status | created_at | updated_at |
+---+--------------------------------------+------------+-----------+---------------------------+----------+--------------------------+--------------------------------------+------------+----------+--------+---------------------+---------------------+
| + | 501daca1-23d1-4928-87b8-bc737d989947 | Sarah | Johnson | sarah.johnson@company.com | 555-0102 | Marketing Manager | 0981e5cd-42e3-4f9d-8d40-8a7cb921c88b | 2022-11-20 | 75000.00 | active | 2025-06-18 14:21:57 | 2025-06-18 14:21:57 |
| + | 6a4b8044-747a-46a5-9cd7-ec6cb1e2b2b2 | David | Brown | david.brown@company.com | 555-0105 | DevOps Engineer | 98933bd8-c20d-4da1-aae7-3abfe2298c04 | 2022-09-15 | 90000.00 | active | 2025-06-18 14:21:57 | 2025-06-18 14:21:57 |
| + | 6fbf7f71-6766-4de5-a1e2-a2e8e3363a75 | John | Smith | john.smith@company.com | 555-0101 | Senior Software Engineer | 98933bd8-c20d-4da1-aae7-3abfe2298c04 | 2023-01-15 | 95000.00 | active | 2025-06-18 14:21:57 | 2025-06-18 14:21:57 |
| + | bc402966-9c1e-467f-ba5d-3aebe2841c97 | Mike | Davis | mike.davis@company.com | 555-0103 | Sales Representative | d116f6bd-fc49-4553-80d5-27348e6030ad | 2023-03-10 | 65000.00 | active | 2025-06-18 14:21:57 | 2025-06-18 14:21:57 |
| + | e0b1b097-ee22-429a-8ed8-9960025d0fd5 | Emily | Wilson | emily.wilson@company.com | 555-0104 | Frontend Developer | 98933bd8-c20d-4da1-aae7-3abfe2298c04 | 2023-02-01 | 80000.00 | active | 2025-06-18 14:21:57 | 2025-06-18 14:21:57 |
+---+--------------------------------------+------------+-----------+---------------------------+----------+--------------------------+--------------------------------------+------------+----------+--------+---------------------+---------------------+
diff --dolt a/teams b/teams
--- a/teams
+++ b/teams
+---+--------------------------------------+-------------+---------------------------------------------------+------------+---------------------+---------------------+
| | id | name | description | manager_id | created_at | updated_at |
+---+--------------------------------------+-------------+---------------------------------------------------+------------+---------------------+---------------------+
| + | 0981e5cd-42e3-4f9d-8d40-8a7cb921c88b | Marketing | Brand management and customer acquisition | NULL | 2025-06-18 14:21:27 | 2025-06-18 14:21:27 |
| + | 988683a9-99e4-440f-b961-a8835c988d93 | HR | Human resources and talent management | NULL | 2025-06-18 14:21:27 | 2025-06-18 14:21:27 |
| + | 98933bd8-c20d-4da1-aae7-3abfe2298c04 | Engineering | Software development and technical infrastructure | NULL | 2025-06-18 14:21:27 | 2025-06-18 14:21:27 |
| + | d116f6bd-fc49-4553-80d5-27348e6030ad | Sales | Revenue generation and client relationships | NULL | 2025-06-18 14:21:27 | 2025-06-18 14:21:27 |
+---+--------------------------------------+-------------+---------------------------------------------------+------------+---------------------+---------------------+CI Tests#
Now, the “coup de gras”. Dolt and DoltHub added Continuous Integration (CI) Capabilities in the fall of 2024. This feature is especially relevant for the agentic AI era we’re entering. With code, CI often catches AI’s mistakes. The same is true for databases.
This was my prompt. Forgive me, I hit enter as I was typing…
> Looks great. please commit.Dolt has a very cool Continuous integration
feature described in this blog:
https://www.dolthub.com/blog/2024-11-14-continuous-integration-on-data/
and this documentation.
⏺ Bash(dolt add .)
⎿ (No content)
⏺ Bash(dolt commit -m "Add dummy test data for teams and employees to
validate schema functionality")
⎿ commit p096igt0tvd5oblvp7b6a8s7o3fgm279 (HEAD
-> main)
Author: Bats Tests <bats@email.fake>
… +4 lines (ctrl+r to expand)
⏺ Fetch(https://www.dolthub.com/blog/2024-11-14-continuous-integration-on-d
ata/)
⎿ Received 125.2KB (200 OK)
⏺ Committed! Dolt's continuous integration feature is really interesting -
it brings GitHub Actions-style workflows specifically to database
development. The key innovation is being able to automatically test data
changes through saved SQL queries with validation rules.
This would be perfect for our employee database to ensure:
- Schema integrity after changes
- Data quality validation
- Referential integrity checks
- Required fields compliance
Would you like me to set up some basic CI workflows for this database to
demonstrate the feature?
> That is why I asked.After a few minutes, my database had CI set up. Figuring out what is in CI is not very user-friendly right now. CI runs saved queries against your Dolt database and validates the result matches an assertion. You first define saved queries using dolt sql --save name -q. Then you make a workflow yaml file referencing the saved queries and assertions. Finally, you import the workflow using dolt ci import. Here’s what claude did after I prompted it with the CI failure.
$ dolt status
On branch main
Untracked tables:
(use "dolt add <table>" to include in what will be committed)
new table: dolt_query_catalog
$ dolt ci ls
Employee Database Validation
$ cat .dolt/workflows/validate_schema.yaml
name: Employee Database Validation
on:
push:
branches:
- main
jobs:
- name: Validate Database Schema
steps:
- name: Check expected tables exist
saved_query_name: validate_tables
expected_rows: "== 2"
- name: Validate table schemas are correct
saved_query_name: validate_schema
expected_rows: "== 14"
- name: Check data integrity constraints
saved_query_name: validate_data_integrity
expected_rows: "== 3"
expected_columns: "== 2"
- name: Validate foreign key relationships
saved_query_name: validate_foreign_keys
expected_rows: "== 2"
$ dolt sql -q "select * from dolt_query_catalog" -r vertical
*************************** 1. row ***************************
id: validate_data_integrity
display_order: 4
name: validate_data_integrity
query: SELECT 'employees_with_teams' as check_name, COUNT(*) as count FROM employees WHERE team_id IS NOT NULL UNION ALL SELECT 'employees_with_valid_emails' as check_name, COUNT(*) as count FROM employees WHERE email LIKE '%@%' UNION ALL SELECT 'teams_with_names' as check_name, COUNT(*) as count FROM teams WHERE name IS NOT NULL AND name <> '';
description:
*************************** 2. row ***************************
id: validate_foreign_keys
display_order: 3
name: validate_foreign_keys
query: SELECT 'orphaned_employees' as check_name, COUNT(*) as count FROM employees e LEFT JOIN teams t ON e.team_id = t.id WHERE e.team_id IS NOT NULL AND t.id IS NULL UNION ALL SELECT 'orphaned_team_managers' as check_name, COUNT(*) as count FROM teams t LEFT JOIN employees e ON t.manager_id = e.id WHERE t.manager_id IS NOT NULL AND e.id IS NULL;
description:
*************************** 3. row ***************************
id: validate_schema
display_order: 2
name: validate_schema
query: SELECT t.table_name, c.column_name, c.data_type, c.is_nullable, c.column_default FROM information_schema.tables t JOIN information_schema.columns c ON t.table_name = c.table_name WHERE t.table_schema = DATABASE() AND t.table_type = 'BASE TABLE' ORDER BY t.table_name, c.ordinal_position;
description:
*************************** 4. row ***************************
id: validate_tables
display_order: 1
name: validate_tables
query: SELECT table_name FROM information_schema.tables WHERE table_schema = DATABASE() AND table_type = 'BASE TABLE' ORDER BY table_name;
description: I committed and pushed the database to DoltHub. But, it failed the first time with this error. Failing tests are common for Claude Code when building code as well. With a quick correction prompt it fixed its work.
> The CI job failed with Failed to run dolt-ci job: Error 1105 (HY000): the
view test-schema-creation.validate_tables already existsIt deleted the views and fixed the saved queries. I pushed and success!
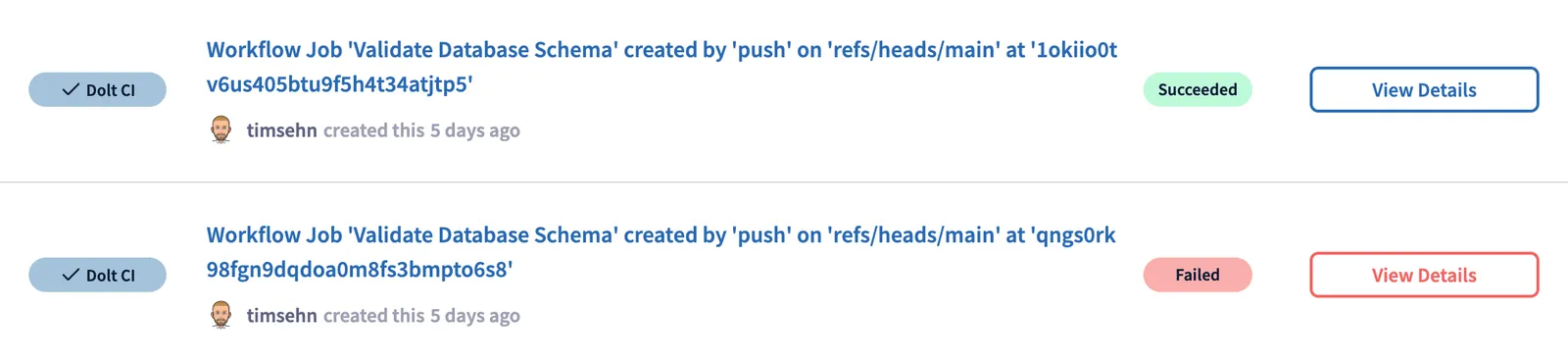
Conclusion#
Claude Code can write code. Claude Code can also do schema design. When paired with Dolt and DoltHub, you get the power of branches for isolated work, diffs for human review, and CI for testing. Dolt is the perfect database for the agentic era of software development we are entering. Have another agentic use case for Dolt you want us to demonstrate? Come by our Discord and tell us. I’ll write an article about it.